

حکایتی هست در این باره که راکفلکر شروع کارش از یک کارخونه کبریت سازی بوده. این داستان مدعی است که این مولتی میلیاردر که زمان جوانی در کارخونه کبریت سازی کار می کرده، روزی پیش مدیرش می ره و می گه ایده ای داره برای چند برابر کردن درآمد کارخونه و در مقابل این قول که در بخشی از این درآمد سهیم بده ایده اش رو می ده:
جعبه کبریت یک کشویی داره که کبریت ها اون تو هستن. این رو برعکس توی جعبه بذارین. هر کس جعبه رو باز می کنه بیشتر کبریت ها به زمین می ریزن و طرف خیلی زودتر از حالتی که کشویی درست نصب شده باشه، مجبور می شه یک جعبه کبریت دیگه بخره. چون کبریت چیز ارزونی است کسی به این امر توجه نخواهد کرد و هیچ کس هم شاکی نخواهد شد و شما چند برابر بیشتر جعبه کبریت خواهید فروخت.
ایده خبیثانه جالبیه ولی چرا اصولا از اول کبریت های کمتری توی جعبه نذاریم؟ اصولا اگر می شه اینجوری پول درآورد مطمئنا کشور ما جای بسیار مناسبی براشه.

برای بررسی این مساله به مغازه می ریم و یک بسته ده تایی کبریت توکلی که ظاهرا تنها بازیگر بزرگ کبریت در ایرانه رو می خریم. اونو به خونه مییاریم. ملحفه سبزمون رو رو زمین پهن می کنیم و به عنوان یک تنبل واقعی، فقط قسمتی که قراره تو عکس باشه رو اتو می کنیم:

و بعد می ریم سراغ ده تا جعبه کبریتی که خریدیم و پشتشون مدعی است که تعداد متوسط کبریتهای هر جعبه چهل تا است:

هر جعبه کبریت رو جدا جدا روی قسمت اتو شده و صاف خالی کرده، عکس می گیریم:

اینکار رو برای هر ده تا جعبه کبریت انجام می دیم و اتاق پر از کبریت رو به قصد نشستن پشت کامپیوتر ترک میکنیم.

اول نیازمند یک برنامه هستیم که بتونه در یک عکس کبریت ها رو بشمره. بعد با یک اسکریپت این برنامه رو برای همه عکس ها اجرا خواهیم کرد. من برای اینکار اول کتابخونههای cv2 رو امتحان کردم ولی با numpy نتیجه بهتر و قشنگ تری گرفتم. در قدم اول کافیه عکس رو بخونیم، اون ۱ به کتابخونه می گه عکس رو بعد از خوندن خاکستری کنه که کار ما رو راحتتر می کنه:
kebrit = scipy.misc.imread(fileName, 1) # gray-scale image
و خروجی چیز شبیه این است:

اینکه تصویر رنگی است به خاطر اینه که به شکل پیش فرض از پالت jet برای نمایش استفاده کرده ایم که تصویر رو به صورت حرارتی نشون می ده. می گن این برای کارهای علمی راحتتر از خاکستری است. به راحتی می بینین که چیزی که می خونیم با اینکه در سبز معمولی یا خاکستری به نظر یکدست مییاد ولی پر از تیزی و نقطه نقطه است. مثل هر عکس دوربینی دیگه. برای حل این مشکل تصویر رو اسموت می کنیم. اسموت کردن در پردازش تصویر معمولا با استفاده از فیلتر گاوس به دست می یاد که کانولوشن گرفتنی است بین این ورودی و تابع گاوس. البته نگران نباشین، من چون سه بار معادلات دیفرانسیل رو افتادم و آخرش هم یکی دیگه به جام امتحان داد، پایه ام قوی شده (:
kebrit_smooth = ndimage.gaussian_filter(kebrit, 6)
حالا متغیر kebrit_smooth یک تصویر نرم شده از تصویر اصلی است:

قدم بعدی اینه که من بیام و یک ترشهولد روی ورودی بذارم و بگم بیخیال هر چیزی بشه که از این عدد خاص کوچکتر است. این عدد با کمی تجربه و کمی سعی خطا به دست اومده. دستور طبیعی باید این می بود:
tresh = 120 labeled, objectsNum = ndimage.label(kebrit_smooth < tresh)
تابع ndimage.label ورودی خودش رو بررسی می کنه و تعداد اجسام به هم پیوسته توی اون رو می شمره. اما مشکل اینه که حتی تک پیکسل های منفرد هم شمرده می شن. برای جلوگیری از این امر من بهش یک ساختار می دم که شکلم حداقل لازمه چنین ساختاری داشته باشه:
tresh = 120 removeOnes = np.ones((3,3), dtype="bool8") labeled, objectsNum = ndimage.label(kebrit_smooth < tresh, structure=removeOnes)
دقت کنین که اون استراکچر در اصل می گه حداقل تصویر قابل تشخیص من باید این باشه:
array([[ True, True, True],
[ True, True, True],
[ True, True, True]], dtype=bool)
و نتیجه اش این می شه که نقطه های منفرد دیگه شمرده نشن. البته انتظارم اینه که با اسموت کردن مرحله قبل این نقطه ها به حداقل رسیده باشن. نتیجه این ترکیب چنین تصویری است:

و خب چنین خروجی متنی ای:
10boxes/IMG_2608.JPG , 29
حالا کافیه یک اسکریپت ساده، همه ده تا فایل رو به اون برنامه بده:
#!/bin/bash
for f in *JPG
do
../count.py $f
done
و به خروجی زیر برسیم:
$ ./doall.sh IMG_2606.JPG , 35 IMG_2607.JPG , 30 IMG_2608.JPG , 29 IMG_2609.JPG , 32 IMG_2610.JPG , 29 IMG_2611.JPG , 33 IMG_2612.JPG , 36 IMG_2613.JPG , 38 IMG_2614.JPG , 37 IMG_2615.JPG , 38
وقتشه سراغ زبون مورد علاقمون R بریم. یک زبان تخصصی برای کارهای آماری و وررفتن با اعداد و ماتریس ها و رفیق رفقاشون. فایل رو می خونیم و بخش مورد نظر رو جدا می کنیم:
> tavakoli <- read.csv(file="results.csv",head=FALSE,sep=",") > matches <- tavakoli[2]$V2
حالا اطلاعات هر جعبه کبریت رو دارم. بذارین یک نگاه سریع بهش بندازیم:
> summary (matches) Min. 1st Qu. Median Mean 3rd Qu. Max. 29.00 30.50 34.00 33.70 36.75 38.00
بعله. می بینیم که میزان متوسط پایینتر از ۳۴ است. یعنی تعداد متوسط این ده قوطی کبریت ۶ تا کمتر از چیزی است که ادعا شده یا به بیان صحیحتر ۱۵٪ کمتر به ما جنس فروختن. جالبیش اینه حتی یک جعبه از این ده جعبه هم به چیزی که ادعا می شد میانگین است نرسیده. بذارین جلوتر بریم:
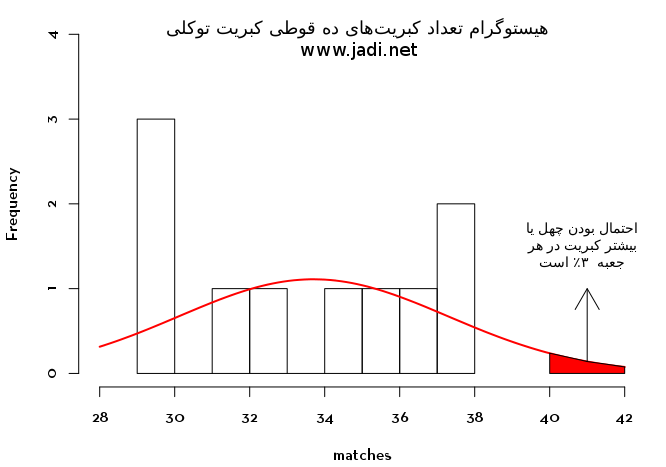
> hist(matches, xlim=c(28,42), ylim=c(0,4), main="هیستوگرام تعداد کبریت های توکلی در هر جعبه", sub="www.jadi.net", breaks=8) > curve(dnorm(x, mean=mean(matches), sd=sd(matches))*10, add=TRUE, col="red", lwd=2)
و روی این نمودار با کمی آمار احتمالات می تونیم احتمال اینکه در یک جعبه کبریت اتفاقی توکلی که خریدهایم و مدعی داشتن ۴۰ کبریت است، چهل یا بیشتر کبریت وجود داشته باشد را حساب کنیم:
> 1-pnorm(40, mean=mean(matches), sd=sd(matches)) #یک منهای سمت چپ نمودار نرمال در نقطه ۴۰ کبریت [1] 0.03970968
بله. با اینکه کبریت توکلی مدعی است در هر جعبه اش تقریبا ۴۰ کبریت وجود داره، برنامه پردازش تصویر و نمودارهای نرمال ما نشون می دن که احتمال اینکه واقعا در یک جعبه کبریت توکلی چهل یا بیشتر کبریت باشه، سه صدم درصد بیشتر نیست
نتیجهها
۰- موسسه استاندارد و حقوق مصرف کننده خاصی نداریم یا هنوز این مساله رو ندیدن
۱- راکفلر باید بیاد پیش تولید کنندههای ما لنگ بندازه
۲- آمار شیرین و فان است
۳- می تونیم با کارهای علمی بامزه هم تفریح کنیم هم چیز یاد بگیریم
مرتبط
- هفته وایبر: منحنی نرمال، اسیدپاشی و اینکه چرا گروههای وایبری ترسناک می شن
- پست مهمان: رابطه استفاده از کلمه مهمل توی وبلاگ جادی و میزان بارون در تهران
و البته مثل همیشه هر جاییش ممکنه اشتباه داشته باشه. خوشحال می شم دوستان حرفه ای اصلاح کنن یا توسعه بدن و به این فکر کنیم که کاش آمار رو اینطوری به ما درس می دادن (:

